Making the Netflix API More Resilient
by Ben Schmaus
The API brokers catalog and subscriber metadata between internal services and Netflix applications on hundreds of device types. If any of these internal services fail there is a risk that the failure could propagate to the API and break the user experience for members.
To provide the best possible streaming experience for our members, it is critical for us to keep the API online and serving traffic at all times. Maintaining high availability and resiliency for a system that handles a billion requests a day is one of the goals of the API team, and we have made great progress toward achieving this goal over the last few months.
Principles of Resiliency
Here are some of the key principles that informed our thinking as we set out to make the API more resilient.
- A failure in a service dependency should not break the user experience for members
- The API should automatically take corrective action when one of its service dependencies fails
- The API should be able to show us what’s happening right now, in addition to what was happening 15–30 minutes ago, yesterday, last week, etc.
Keep the Streams Flowing
As stated in the first principle above, we want members to be able to continue instantly watching movies and TV shows streaming from Netflix when server failures occur, even if the experience is slightly degraded and less personalized. To accomplish this we’ve restructured the API to enable graceful fallback mechanisms to kick in when a service dependency fails. We decorate calls to service dependencies with code that tracks the result of each call. When we detect that a service is failing too often we stop calling it and serve fallback responses while giving the failing service time to recover. We then periodically let some calls to the service go through and if they succeed then we open traffic for all calls.
If this pattern sounds familiar to you, you’re probably thinking of the CircuitBreaker pattern from Michael Nygard’s book “Release It! Design and Deploy Production-Ready Software”, which influenced the implementation of our service dependency decorator code. Our implementation goes a little further than the basic CircuitBreaker pattern in that fallbacks can be triggered in a few ways:
- A request to the remote service times out
- The thread pool and bounded task queue used to interact with a service dependency are at 100% capacity
- The client library used to interact with a service dependency throws an exception
These buckets of failures factor into a service’s overall error rate and when the error rate exceeds a defined threshold then we “trip” the circuit for that service and immediately serve fallbacks without even attempting to communicate with the remote service.
Each service that’s wrapped by a circuit breaker implements a fallback using one of the following three approaches:
- Custom fallback — in some cases a service’s client library provides a fallback method we can invoke, or in other cases we can use locally available data on an API server (eg, a cookie or local JVM cache) to generate a fallback response
- Fail silent — in this case the fallback method simply returns a null value, which is useful if the data provided by the service being invoked is optional for the response that will be sent back to the requesting client
- Fail fast — used in cases where the data is required or there’s no good fallback and results in a client getting a 5xx response. This can negatively affect the device UX, which is not ideal, but it keeps API servers healthy and allows the system to recover quickly when the failing service becomes available again.
Ideally, all service dependencies would have custom fallbacks as they provide the best possible user experience (given the circumstances). Although that is our goal, it’s also very challenging to maintain complete fallback coverage for many service dependencies. So the fail silent and fail fast approaches are reasonable alternatives.
Real-time Stats Drive Software and Diagnostics
I mentioned that our circuit breaker/fallback code tracks and acts on requests to service dependencies. This code counts requests to each service dependency over a 10 second rolling window. The window is rolling in the sense that request stats that are older than 10 seconds are discarded; only the results of requests over the last 10 seconds matter to the code. We also have a dashboard that’s wired up to these same stats that shows us the state of our service dependencies for the last 10 seconds, which comes in really handy for diagnostics.
You might ask, “Do you really need a dashboard that shows you the state of your service dependencies for the last 10 seconds?” The Netflix API receives around 20,000 requests per second at peak traffic. At that rate, 10 seconds translates to 200,000 requests from client devices, which can easily translate to 1,000,000+ requests from the API into upstream services. A lot can happen in 10 seconds, and we want our software to base its decision making on what just happened, not what was happening 10 or 15 minutes ago. These real-time insights can also help us identify and react to issues before they become member-facing problems. (Of course, we have charts for identifying trends beyond the 10 second window, too.)
Circuit Breaker in Action
Now that I’ve described the basics of the service dependency decorator layer that we’ve built, here’s a real world example that demonstrates the value it can provide.The data that the API uses to respond to certain requests is stored in a database but it’s also cached as a Java object in a shared cache. Upon receiving one of these requests, the API looks in the shared cache and if the object isn’t there it queries the database. One day we discovered a bug where the API was occasionally loading a Java object into the shared cache that wasn’t fully populated, which had the effect of intermittently causing problems on certain devices.
Once we discovered the problem, we decided to bypass the shared cache and go directly to the database while we worked on a patch. The following chart shows cache hits and that disabling the cache had the expected effect of dropping hits to zero.
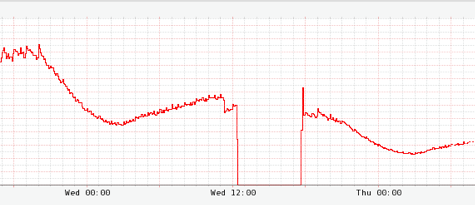
What we weren’t counting on was getting throttled by our database for sending it too much traffic. Fortunately, we implemented custom fallbacks for database selects and so our service dependency layer started automatically tripping the corresponding circuit and invoking our fallback method, which checked a local query cache on database failure. This next chart shows the spike in fallback responses.
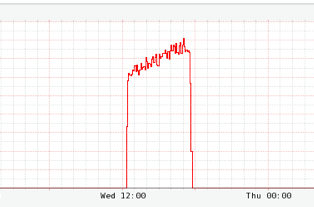
The fallback query cache had most of our active data set and so the overall impact to member experience was very low as can be seen by the following chart, which shows a minimal effect on overall video views. (The red line is video views per second this week and the black line is the same metric last week.)
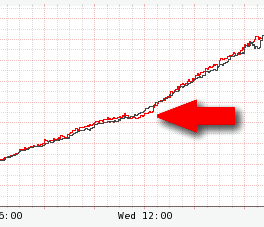
Show Me, Don’t Tell Me
While this was happening, we were able to see exactly what the system was doing by looking at our dashboard, which processes a data stream that includes the same stats used by the circuit breaker code. Here’s an excerpt that shows what the dashboard looked like during the incident.

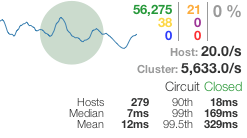
The red 80% in the upper right shows the overall error rate for our database select circuit, and the “Open” and “Closed” counts show that the majority of server instances (157 of 200) were serving fallback responses. The blue count is the number of short-circuited requests that were never sent to the database server.
The dashboard is based on the classic green, yellow, red traffic light status page pattern and is designed to be quickly scannable. Each circuit (we have ~60 total at this point) has a circle to the left that encodes call volume (size of the circle — bigger means more traffic) and health (color of the circle — green is healthy and red indicates a service that’s having problems). The sparkline indicates call volume over a 2 minute rolling window (though the stats outside of the 10 second window are just used for display and don’t factor into the circuit breaker logic).
Here’s an example of what a healthy circuit looks like.
And here’s a short video showing the dashboard in action:
The Future of API Resiliency
Our service dependency layer is still very new and there are a number of improvements we want to make, but it’s been great to see the thinking translate into higher availability and a better experience for members. That said, a ton of work remains to bolster the system, increase fallback coverage, refine visualizations and insights, etc. If these kinds of challenges excite you, especially at large scale, in the cloud, and on a small, fast-moving team, we’re actively looking for DevOps engineers.
Originally published at techblog.netflix.com on December 8, 2011.

