Object Cache for Scaling Video Metadata Management
As the largest Internet TV network, one of the most interesting challenges we face at Netflix is scaling services to the ever-increasing demands of over 36 million customers from over 40 countries.
Each movie or TV show on Netflix is described by a complex set of metadata. This includes the obvious information such as title, genre, synopsis, cast, maturity rating etc. It also includes links to images, trailers, encoded video files, subtitles and the individual episodes and seasons. Finally there are many tags that are used to create custom genres, such as “upbeat”, “cerebral”, “strong female lead”. These all have to be translated into many languages, so the actual text is tokenized and encoded.
This metadata must be made available for several different services, which each require a different facet of the data. Front-end services for display purposes need links to images, while algorithms that do discovery and recommendations use the tags extensively and search thousands of movies looking for the best few to show to a user. Powering this while utilizing resources extremely efficiently is one of the key goals of our Video Metadata Services (VMS) Platform.
Some examples of functionality enabled by VMS are metadata correlation for recommending titles, surfacing metadata such as actors and synopsis to help users make viewing choices (example below), and enabling streaming decisions based on device and bit rates.
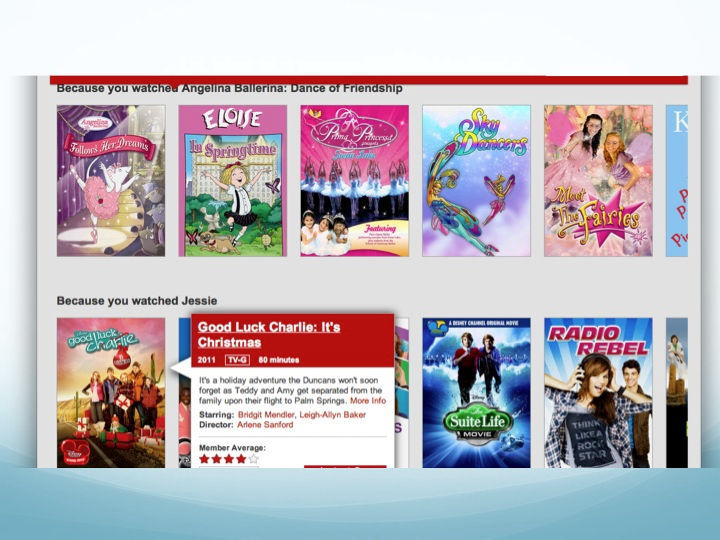
As we set out to build the platform, there were a few key requirements to address:
- Handle over a 100 billion requests a day with extremely low latency for user-facing apps
- Handle very large dataset size of 20–30GB across all countries and devices
- Work with high data complexity metadata processing (described in detail here)
- Quick start-up times to make auto-scaling work efficiently
We took advantage of the fact that real-time access to the very latest data is not necessary. For new content flowing to the site, it has a contract-start-time as part of the metadata, so the metadata is updated well in advance of the new content being ready to show, and the personalization algorithms ignore the title until the start time is reached. The main reason to push an update is to fix metadata errors.
We used the following approach in our initial cloud deployment:
- Implement a server that interacts with existing relational database systems, generates data snapshots periodically and uploads them to an S3 bucket
- One server was configured to process data per country and generate data snapshots after evaluating data correlation and applying business and filter logic
- A client-side Object Cache loads the relevant snapshots based on client application configuration and makes the data available to the application as in memory Java objects
The cache is then refreshed periodically based on snapshots generated by VMS servers, with a variable frequency fine-tuned based on application. There is server-side processing for compression and various optimizations to enable very compact data storage in memory, followed by deserialization and further optimization on the client-side before constructing and refreshing the cache. The diagram below shows the architecture with this implementation.

This worked very well for us and was running in production for some time, but we faced a new challenge as Netflix expanded internationally. In this architecture, we needed to configure server instances and process metadata for each country, whether it was country-specific or global. For example metadata such as trailer data, subtitles, dubbing, language translations and localization as well as contract information varies based on the country but metadata such as genre, cast, director do not. We started out serving the US catalog, added Canada as a second server, but when we added Latin America, we had to be able to serve different content in every jurisdiction, which added 42 more variants that needed their own server. The UK, Ireland and the four Nordic countries added six more.
In addition to the operational overhead of 50 servers, this also resulted in an increase in the client object cache footprint as there was duplication of data across the setup for countries. Also the start-up time on the client went up as it was working hard to de-duplicate data that was global across countries to manage the footprint. This processing was also involved at each refresh impacting user-facing application behavior. This prompted us to look for a solution that would help us scale on these fronts while supporting the increasing business needs.
In a previous post we shared results from a case study for memory optimization with the NetflixGraph Library used extensively by our recommendations engine.
Following these encouraging results and also based on identifying areas of duplicate data or processing, we made a few changes in the architecture:
- Streamlined our VMS Server to be structured around islands (a collection of countries that have similar characteristics) instead of per country
- Moved metadata processing and de-deduplication to the server-side and applied memory optimization techniques based on the NetflixGraph to the blobs generated
- Enabled operationally easier configuration based on what metadata an application was interested in rather than all the data
The architecture after these changes is shown below with the key changes highlighted.

This helped achieve a huge reduction in our cache memory footprint as well as significantly better warm-up and refresh times, in addition to simplifying operational management by requiring fewer servers.
VMS leverages and integrates with several Open Source solutions available from Netflix such as Karyon, Netflix Graph, Governator, Curator, and Archaius and is a major user of our Open Source ecosystem. The entire Metadata Platform Infrastructure is also tested using the Chaos Monkey and other members of the Simian Army to ensure it is resilient.
Conclusions
An object cache with periodic refreshes is a good solution when there is a low latency requirement with relatively high tolerance for staleness for large amounts of data. Furthermore, moving heavy data processing to the server-side improves client-side cache performance characteristics, especially when the request-response pattern between the client and the server does not involve real-time queries.
Questions we continue to work on include:
- How best to add a lot of extra metadata just for Netflix original series like House of Cards?
- How do we ensure cache efficiency with ever-changing business landscape and needs?
- How can we ensure that updates can propagate through system components quickly and become available to user-facing applications and services right away?
- How quickly can data issues be identified/resolved for a seamless user experience?
Given the very distributed nature of the processing and systems, tooling is as important as building solid data propagation mechanisms, data correctness and memory optimization.
We have more work planned around the above, including moving to an event-based architecture for faster metadata propagation and further structural streamlining of the blob images so we can remain resilient as our data size increases over time. Stay tuned for more on these in upcoming blog posts.
If you are interested in solving such challenges, check out jobs.netflix.com or reach out to me on LinkedIn, we are always looking for top-notch developers and QA engineers to join our team.
See Also:
Originally published at techblog.netflix.com on April 7, 2017.

