Announcing Electric Eye

Netflix ships on a wide variety of devices, ranging from small thumbdrive-sized HDMI dongles to ultra-massive 100”+ curved screen HDTVs, and the wide variety of form factors leads to some interesting challenges in testing. In this post, we’re going to describe the genesis and evolution of Electric Eye, an automated computer vision and audio testing framework created to help test Netflix on all of these devices.
Let’s start with the Twenty-First Century Communications and Video Accessibility Act of 2010, or CCVA for short. Netflix creates closed caption files for all of our original programming, like Marvel’s Daredevil, Orange is the New Black, and House of Cards, and we serve closed captions for any content that we have captions for. Closed captions are sent to devices as Timed Text Markup Language (TTML), and describe what the captions should say, when and where they should appear, and when they should disappear, amongst other things. The code to display captions on devices is a combination of JavaScript served by our servers and native code on the devices. This led to an interesting question: How can we make sure that captions are showing up completely and on time? We were having humans do the work, but occasionally humans make mistakes. Given that CCVA is the law of the land, we wanted a relatively error-proof way of ensuring compliance.
If we only ran on devices with HDMI-out, we might be able to use something like stb-tester to do the work. However, we run on a wide variety of television sets, not all of which have HDMI-out. Factor in curved screens and odd aspect ratios, and it was starting to seem like there may not be a way to do this reliably for every device. However, one of the first rules of software is that you shouldn’t let your quest for perfection get in the way of making an incremental step forward.
We decided that we’d build a prototype using OpenCV to try to handle flat-screen televisions first, and broke the problem up into two different subproblems: obtaining a testable frame from the television, and extracting the captions from the frame for comparison. To ensure our prototype didn’t cost a lot of money, we picked up a few cheap 1080p webcams from a local electronics store.
OpenCV has functionality built in to detect a checkerboard pattern on a flat surface and generate a perspective-correction matrix, as well as code to warp an image based on the matrix, which made frame acquisition extremely easy. It wasn’t very fast (manually creating a lookup table using the perspective-correction matrix for use with remap improves the speed significantly), but this was a proof of concept. Optimization could come later.
The second step was a bit tricky. Television screens are emissive, meaning that they emit light. This causes blurring, ghosting, and other issues when they are being recorded with a camera. In addition, we couldn’t just have the captions on a black screen since decoding video could potentially cause enough strain on a device to cause captions to be delayed or dropped. Since we wanted a true torture test, we grabbed video of running water (one of the most strenuous patterns to play back due to its unpredictable nature), reduced its brightness by 50%, and overlaid captions on top of it. We’d bake “gold truth” captions into the upper part of the screen, show the results from parsed and displayed TTML in the bottom, and look for differences.
When we tested using HDMI capture, we could apply a thresholding algorithm to the frame and get the captions out easily.

When we worked with the result from the webcam, things weren’t as nice.

Glare from ceiling lights led to unique issues, and even though the content was relatively high contrast, the emissive nature of the screen caused the water to splash through the captions.
While all of the issues that we found with the prototype were a bit daunting, they were eventually solved through a combination of environmental corrections (diffuse lighting handled most of the glare issues) and traditional OpenCV image cleanup techniques, and it proved that we could use CV to help test Netflix. The prototype was eventually able to reliably detect deltas of as little as 66ms, and it showed enough promise to let us create a second prototype, but also led to us adopting some new requirements.
First, we needed to be real-time on a reasonable machine. With our unoptimized code using the UI framework in OpenCV, we were getting ~20fps on a mid-2014 MacBook Pro, but we wanted to get 30fps reliably. Second, we needed to be able to process audio to enable new types of tests. Finally, we needed to be cross-platform. OpenCV works on Windows, Mac, and Linux, but its video capture interface doesn’t expose audio data.
For prototype #2, we decided to switch over to using a creative coding framework named Cinder. Cinder is a C++ library best known for its use by advertisers, but it has OpenCV bindings available as a “CinderBlock” as well as a full audio DSP library. It works on Windows and Mac, and work is underway on a Linux fork. We also chose a new test case to prototype: A/V sync. Getting camera audio and video together using Cinder is fairly easy to do if you follow the tutorials on the Cinder site.
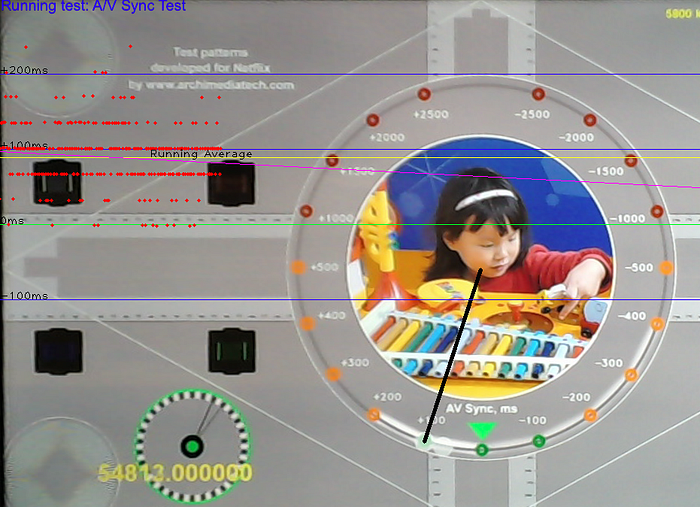
The content for this test already existed on Netflix: Test Patterns. These test patterns were created specifically for Netflix by Archimedia to help us test for audio and video issues. On the English 2.0 track, a 1250Hz tone starts playing 400ms before the ball hits the bottom, and once there, the sound transitions over to a 200ms-long 1000Hz tone. The highlighted areas on the circle line up with when these tones should play. This pattern repeats every six seconds.
For the test to work, we needed to be able to tell what sound was playing. Cinder provides a MonitorSpectralNode class that lets us figure out dominant tones with a little work. With that, we could grab each frame as it came in, detect when the dominant tone changed from 1250Hz to 1000Hz, display the last frame that we got from the camera, and *poof* a simple A/V sync test.

The next step was getting it so that we could find the ball on the test pattern and automate the measurement process. You may notice that in this image, you can see three balls: one at 66ms, one at 100ms, and one at 133ms. This is a result of a few factors: the emissive nature of the display, the camera being slightly out of sync with the TV, and pixel response time.
Through judicious use of image processing, histogram equalization, and thresholding, we were able to get to the point where we could detect the proper ball in the frame and use basic trigonometry to start generating numbers. We only had ~33ms of precision and +/-33ms of accuracy per measurement, but with sufficient sample sizes, the data followed a bell curve around what we felt we could report as an aggregate latency number for a device.
Cinder isn’t perfect. We’ve encountered a lot of hardware issues for the audio pipeline because Cinder expects all parts of the pipeline to work at the same frequency. The default audio frequency on a MacBook Pro is 44.1kHz, unless you hook it up to a display via HDMI, where it changes to 48kHz. Not all webcams support both 44.1kHz and 48kHz natively, and when we can get device audio digitally, it should be (but isn’t always) 48kHz. We’ve got a workaround in place (forcing the output frequency to be the same as the selected input), and hope to have a more robust fix we can commit to the Cinder project around the time we release.
After five months of prototypes, we’re now working on version 1.0 of Electric Eye, and we’re planning on releasing the majority of the code as open source shortly after its completion. We’re adding extra tests, such as mixer latency and audio dropout detection, as well as looking at future applications like motion graphics testing, frame drop detection, frame tear detection, and more.
Our hope is that even if testers aren’t able to use Electric Eye in their work environments, they might be able to get ideas on how to more effectively utilize computer vision or audio processing in their tests to partially or fully automate defect detection, or at a minimum be motivated to try to find new and innovative ways to reduce subjectivity and manual effort in their testing.
[Update 10/23/2015: Fixed an outdated link to Cinder’s tutorials.]
Originally published at techblog.netflix.com on September 22, 2015.

