Kafka Inside Keystone Pipeline
This is the second blog of our Keystone pipeline series. Please refer to the first part for overview and evolution of the Keystone pipeline:
In summary, the Keystone pipeline is a unified event publishing, collection, and routing infrastructure for both batch and stream processing.
We have two sets of Kafka clusters in Keystone pipeline: Fronting Kafka and Consumer Kafka. Fronting Kafka clusters are responsible for getting the messages from the producers which are virtually every application instance in Netflix. Their roles are data collection and buffering for downstream systems. Consumer Kafka clusters contain a subset of topics routed by Samza for real-time consumers.
We currently operate 36 Kafka clusters consisting of 4,000+ broker instances for both Fronting Kafka and Consumer Kafka. More than 700 billion messages are ingested on an average day. We are currently transitioning from Kafka version 0.8.2.1 to 0.9.0.1.
Design Principles
Given the current Kafka architecture and our huge data volume, to achieve lossless delivery for our data pipeline is cost prohibitive in AWS EC2. Accounting for this, we’ve worked with teams that depend upon our infrastructure to arrive at an acceptable amount of data loss, while balancing cost. We’ve achieved a daily data loss rate of less than 0.01%. Metrics are gathered for dropped messages so we can take action if needed.
The Keystone pipeline produces messages asynchronously without blocking applications. In case a message cannot be delivered after retries, it will be dropped by the producer to ensure the availability of the application and good user experience. This is why we have chosen the following configuration for our producer and broker:
- acks = 1
- block.on.buffer.full = false
- unclean.leader.election.enable = true
Most of the applications in Netflix use our Java client library to produce to Keystone pipeline. On each instance of those applications, there are multiple Kafka producers, with each producing to a Fronting Kafka cluster for sink level isolation. The producers have flexible topic routing and sink configuration which are driven via dynamic configuration that can be changed at runtime without having to restart the application process. This makes it possible for things like redirecting traffic and migrating topics across Kafka clusters. For non-Java applications, they can choose to send events to Keystone REST endpoints which relay messages to fronting Kafka clusters.
For greater flexibility, the producers do not use keyed messages. Approximate message ordering is re-established in the batch processing layer (Hive / Elasticsearch) or routing layer for streaming consumers.
We put the stability of our Fronting Kafka clusters at a high priority because they are the gateway for message injection. Therefore we do not allow client applications to directly consume from them to make sure they have predictable load.
Challenges of running Kafka in the Cloud
Kafka was developed with data center as the deployment target at LinkedIn. We have made notable efforts to make Kafka run better in the cloud.
In the cloud, instances have an unpredictable life-cycle and can be terminated at anytime due to hardware issues. Transient networking issues are expected. These are not problems for stateless services but pose a big challenge for a stateful service requiring ZooKeeper and a single controller for coordination.
Most of our issues begin with outlier brokers. An outlier may be caused by uneven workload, hardware problems or its specific environment, for example, noisy neighbors due to multi-tenancy. An outlier broker may have slow responses to requests or frequent TCP timeouts/retransmissions. Producers who send events to such a broker will have a good chance to exhaust their local buffers while waiting for responses, after which message drop becomes a certainty. The other contributing factor to buffer exhaustion is that Kafka 0.8.2 producer doesn’t support timeout for messages waiting in buffer.
Kafka’s replication improves availability. However, replication leads to inter-dependencies among brokers where an outlier can cause cascading effect. If an outlier slows down replication, replication lag may build up and eventually cause partition leaders to read from the disk to serve the replication requests. This slows down the affected brokers and eventually results in producers dropping messages due to exhausted buffer as explained in previous case.
During our early days of operating Kafka, we experienced an incident where producers were dropping a significant amount of messages to a Kafka cluster with hundreds of instances due to a ZooKeeper issue while there was little we could do. Debugging issues like this in a small time window with hundreds of brokers is simply not realistic.
Following the incident, efforts were made to reduce the statefulness and complexity for our Kafka clusters, detect outliers, and find a way to quickly start over with a clean state when an incident occurs.
Kafka Deployment Strategy
The following are the key strategies we used for deploying Kafka clusters
- Favor multiple small Kafka clusters as opposed to one giant cluster. This reduces the operational complexity for each cluster. Our largest cluster has less than 200 brokers.
- Limit the number of partitions in each cluster. Each cluster has less than 10,000 partitions. This improves the availability and reduces the latency for requests/responses that are bound to the number of partitions.
- Strive for even distribution of replicas for each topic. Even workload is easier for capacity planning and detection of outliers.
- Use dedicated ZooKeeper cluster for each Kafka cluster to reduce the impact of ZooKeeper issues.
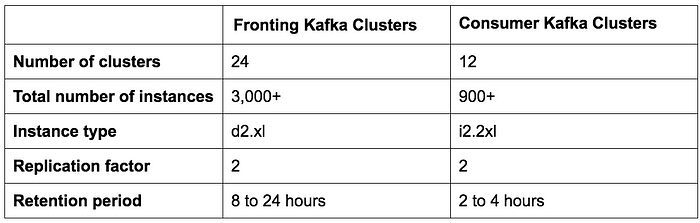
The following table shows our deployment configurations.
Kafka Failover
We automated a process where we can failover both producer and consumer (router) traffic to a new Kafka cluster when the primary cluster is in trouble. For each fronting Kafka cluster, there is a cold standby cluster with desired launch configuration but minimal initial capacity. To guarantee a clean state to start with, the failover cluster has no topics created and does not share the ZooKeeper cluster with the primary Kafka cluster. The failover cluster is also designed to have replication factor 1 so that it will be free from any replication issues the original cluster may have.
When failover happens, the following steps are taken to divert the producer and consumer traffic:
- Resize the failover cluster to desired size.
- Create topics on and launch routing jobs for the failover cluster in parallel.
- (Optionally) Wait for leaders of partitions to be established by the controller to minimize the initial message drop when producing to it.
- Dynamically change the producer configuration to switch producer traffic to the failover cluster.
The failover scenario can be depicted by the following chart:
With the complete automation of the process, we can do failover in less than 5 minutes. Once failover has completed successfully, we can debug the issues with the original cluster using logs and metrics. It is also possible to completely destroy the cluster and rebuild with new images before we switch back the traffic. In fact, we often use failover strategy to divert the traffic while doing offline maintenance. This is how we are upgrading our Kafka clusters to new Kafka version without having to do the rolling upgrade or setting the inter-broker communication protocol version.
Development for Kafka
We developed quite a lot of useful tools for Kafka. Here are some of the highlights:
Producer sticky partitioner
This is a special customized partitioner we have developed for our Java producer library. As the name suggests, it sticks to a certain partition for producing for a configurable amount of time before randomly choosing the next partition. We found that using sticky partitioner together with lingering helps to improve message batching and reduce the load for the broker. Here is the table to show the effect of the sticky partitioner:

Rack aware replica assignment
All of our Kafka clusters spans across three AWS availability zones. An AWS availability zone is conceptually a rack. To ensure availability in case one zone goes down, we developed the rack (zone) aware replica assignment so that replicas for the same topic are assigned to different zones. This not only helps to reduce the risk of a zone outage, but also improves our availability when multiple brokers co-located in the same physical host are terminated due to host problems. In this case, we have better fault tolerance than Kafka’s N — 1 where N is the replication factor.
The work is contributed to Kafka community in KIP-36 and Apache Kafka Github Pull Request #132.
Kafka Metadata Visualizer
Kafka’s metadata is stored in ZooKeeper. However, the tree view provided by Exhibitor is difficult to navigate and it is time consuming to find and correlate information.
We created our own UI to visualize the metadata. It provides both chart and tabular views and uses rich color schemes to indicate ISR state. The key features are the following:
- Individual tab for views for brokers, topics, and clusters
- Most information is sortable and searchable
- Searching for topics across clusters
- Direct mapping from broker ID to AWS instance ID
- Correlation of brokers by the leader-follower relationship
The following are the screenshots of the UI:
Monitoring
We created a dedicated monitoring service for Kafka. It is responsible for tracking:
- Broker status (specifically, if it is offline from ZooKeeper)
- Broker’s ability to receive messages from producers and deliver messages to consumers. The monitoring service acts as both producer and consumer for continuous heartbeat messages and measures the latency of these messages.
- For old ZooKeeper based consumers, it monitors the partition count for the consumer group to make sure each partition is consumed.
- For Keystone Samza routers, it monitors the checkpointed offsets and compares with broker’s log offsets to make sure they are not stuck and have no significant lag.
In addition, we have extensive dashboards to monitor traffic flow down to a topic level and most of the broker’s metrics.
Future plan
We are currently in process of migrating to Kafka 0.9, which has quite a few features we want to use including new consumer APIs, producer message timeout and quotas. We will also move our Kafka clusters to AWS VPC and believe its improved networking (compared to EC2 classic) will give us an edge to improve availability and resource utilization.
We are going to introduce a tiered SLA for topics. For topics that can accept minor loss, we are considering using one replica. Without replication, we not only save huge on bandwidth, but also minimize the state changes that have to depend on the controller. This is another step to make Kafka less stateful in an environment that favors stateless services. The downside is the potential message loss when a broker goes away. However, by leveraging the producer message timeout in 0.9 release and possibly AWS EBS volume, we can mitigate the loss.
Stay tuned for future Keystone blogs on our routing infrastructure, container management, stream processing and more!
— by Real-Time Data Infrastructure Team
Allen Wang, Steven Wu, Monal Daxini, Manas Alekar, Zhenzhong Xu, Jigish Patel, Nagarjun Guraja, Jonathan Bond, Matt Zimmer, Peter Bakas, Kunal Kundaje
Originally published at techblog.netflix.com on April 27, 2016.

