Automated testing on devices
As part of the Netflix SDK team, our responsibility is to ensure the new release version of the Netflix application is thoroughly tested to its highest operational quality before deploying onto gaming consoles and distributing as an SDK (along with a reference application) to Netflix device partners; eventually making its way to millions of smart TV’s and set top boxes (STB’s). Overall, our testing is responsible for the quality of Netflix running on millions of gaming consoles and internet connected TV’s/STB’s.
Unlike software releases on the server side, the unique challenge with releases on devices is that there can be no red/black pushes or immediate rollbacks in case of failure. If there is a bug in the client, the cost of fixing the issue after the code has been shipped on the client device is quite high. Netflix has to re-engage with various partners whose devices might already have been certified for Netflix, kicking off the cycle again to re-certify the devices once the fix has been applied, costing engineering time both externally and internally. All the while, customers might not have a workaround to the problem, hence exposing them to suboptimal Netflix experience. The most obvious way to avoid this problem is to ensure tests are conducted on devices in order to detect application regressions well before the release is shipped.
This is a first part on a series of posts to describe key concepts and infrastructure we use to automate functional, performance, and stress testing the Netflix SDK on a number of devices.
Aspirational Goals
Over the years, our experience with testing the Netflix application using both manual and automated means taught us several lessons. So when the time came to redesign our automation system to go to the next level and scale up we made sure to set them as core goals.
Low setup cost / High test “agility”
Tests should not be harder to create and/or use when automation is used. In particular tests that are simple to run manually should stay simple to run in the automation. This means that using automation should have close to zero setup cost (if not none). This is important to make sure that creating new tests and debugging existing ones is both fast and painless. This also ensures the focus stays on the test and features in test as long as possible.
No test structure constraint
Using an automation system should not constrain tests to be written in a particular format. This is important in order to allow future innovation in how tests are written. Furthermore different teams (we interact with teams responsible for platform, security, playback/media/ UI, etc) might come up with different ways to structure their tests in order to better suit their needs. Making sure the automation system is decoupled from the test structure increase its reusability.
Few layers at the test level
When building a large scale system, it is easy to end up with too many layers of abstraction. While this isn’t inherently bad in many cases, it becomes an issue when those layers are also added in the tests themselves in order to allow them to integrate with automation. Indeed the further away you are from the feature you actually test, the harder it is to debug when issues arise: so many more things outside of the application under test could have gone wrong.
In our case we test Netflix on devices, so we want to make sure that the tests run on the device itself calling to functions as close as possible to the SDK features being tested.
Support important device features
Device management consumes a lot of time when done manually and therefore is a big part of a good automation system. Since we test a product that is being developed, we need the ability to change builds on the fly and deploy them to devices. Extracting log files and crash dumps is also very important to automate in order to streamline the process of debugging test failure.
Designing automation
With these goals in place, it was clear that our team needed a system providing the necessary automation and device services while at the same time staying out of the way of testing as much as possible.
This required rethinking existing frameworks and creating a new kind of automation ecosystem. In order for automation to provide that flexibility, we needed the automation system to be lean, modular and require external services only when absolutely needed for testing a feature, that is to say only if the functionality cannot be done directly from the application on the device (for example suspend the application or manipulate the network).
Reducing the use of external services to the strict minimum has a few benefits:
- It ensures that the logic about the test resides within the test itself as much as possible. This improves readability, maintenance and debuggability of the test.
- Most tests end up having no external dependencies allowing developers trying to reproduce a bug to run the test with absolutely no setup using the tools they are used to.
- The test case author can focus on testing the functionality of the device without worrying about external constraints.
At the simplest level, we needed to have two separate entities:
Test Framework
A software abstraction helping the writing of test cases by exposing functions taking care of the test flow of control.
A test framework is about helping writing tests and should be as close as possible to the device/application been tested in order to reduce the moving parts needed to be checked when debugging a test failure.
There could be many of them so that different teams can structure their tests in a way that matches their needs.
Automation Services
A set of external backend services helping with the management of devices, automating execution of tests and when absolutely required providing external features for testing. Automation services should be built in the most standalone manner as possible. Reducing ties between services allows for better reusability, maintenance, debugging and evolution. For example services which aid in starting the test, collecting information about the test run, validating test results can be delegated to individual microservices. These microservices aid in running the test independently and are not required to run a test. Automation service should only provide service and should not control the test flow.
For instance, the test can ask an external service to restart the device as part of test flow. But the service should not be dictating the test to restart the device and control test flow.
Building a Plug and Play Ecosystem
When it came to designing automation services, we looked at what was needed from each of these services.
Device Management
While the tests themselves are automated, conducting tests on a wide range of devices requires a number of custom steps such as flashing, upgrading, and launching the application before the test starts as well as collecting logs and crash dumps after the test ends. Each of these operations can be completely different on each device. We needed a service abstracting the device specific information and providing a common interface for different devices
Test Management
Writing tests is only a small part of the story: the following must also be taken care of:
- Organizing them in groups (test suites)
- Choosing when to run them
- Choosing what configuration to run them with
- Storing their results
- Visualizing their results
Network Manipulation
Testing the Netflix application experience on a device with fluctuating bandwidth is a core requirement for ensuring high quality uninterrupted playback experience. We needed a service which could change network conditions including traffic shaping and DNS manipulation.
File Service
As we start collecting builds for archival purpose or for storing huge log files, we needed a way to store and retrieve these files and file service was implemented to assist with this.
Test Runner
Each service being fully independent we needed an orchestrator that would talk to the separate services in order to get and prepare devices before tests are run and collecting results after the tests ends.
With the above mentioned design choices in mind, we built the following automation system.
The services described below evolved to meet the above specified needs with the principles of being as standalone as possible and not tied into the testing framework. These concepts were put in practice as described below.
Device service
The device service abstracts the technical details required to manage a device from start to end. By exposing a simple unified RESTful interface for all type of devices, consumers of this service no longer need to have any device specific knowledge: they can use all and any devices as if they were the same.
The logic of managing each type of devices in not directly implemented on the device service itself but instead delegated to other independent micro-services called device handlers.
This brings flexibility is adding support of new type of devices since device handlers can be written in any programing language using their own choice of REST APIs and existing handlers can easily be integrated with the device service. Some handlers can also sometimes require a physical connection to the device therefore decoupling the device service from the device handlers gives flexibility in where to locate them.
For each request received, the role of the device service is to figure out which device handler to contact and proxy the request to it after having adapted it to the set of REST API the device handler interfaces with.
Let us look at a more concrete example of this… The action for installing a build on PS4 for example is very different than installing a build on Roku. One relies on code written in C# interfacing with ProDG Target Manager running on Windows (for PlayStation) and the other written in Node.js running on Linux. The PS4 and Roku device handlers both implement their own device specific installation procedure.
If the device service needs to talk to a device, it needs to know the device specific information. Each device, with its own unique identifier is stored and accessible by the device service as a device map object, containing information regarding the device needed by the handler. For example:
- Device IP or hostname
- Device Mac address (optional)
- Handler IP or hostname
- Handler Port
- Bifrost IP or hostname (Network service)
- Powercycle IP or hostname (remote power management service)
The device map information is populated when adding device into our automation for the first time.
When a new device type is introduced for testing, a specific handler for that device is implemented and exposed by the device service. The device service supports the following common set of device methods:
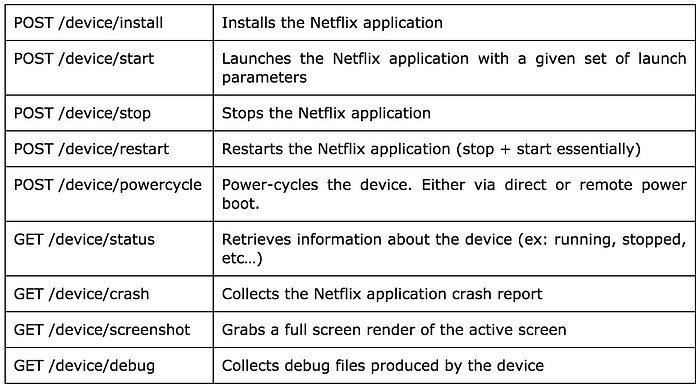
Note that each of these endpoints require a unique device identifier to be posted to the request. This identifier (similar to a serial number) is tied to the device being operated.
Keeping the service simple allows it to be quite extensible. Introducing additional capability for devices can be easily done, and if a device does not support the capability, it simply NOOPs it.
The device service also acts as a device pooler:

Here are some pictures of some of the devices that we are running in the lab for automation. Notice the little mechanical hand near the power button for Xbox 360. This is a custom solution that we put together just for Xbox 360 as this device requires manual button press to reboot it. We decided to automate this manual process by designing a mechanical arm connected to a raspberry pi which sends control over to the hand for moving and pressing the power button. This action was added to the Xbox 360 device handler. The powercycle endpoint of device service calls the power cycle handler of Xbox 360. This action is not necessary for PS3 or PS4 and is not implemented in those handlers.
Test service
The Test Service is the bookkeeper of a running test case session. Its purpose is to mark the start of a test case, records status changes, log messages, metadata, links to files (logs/crash minidumps collected throughout the test) and data series emitted by the test case until test completion. The service exposes simple endpoints invoked by the test framework running the test case:

A test framework will typically internally call those endpoints as follow:
- Once the test has started, a call to POST /test/start is made
- A periodic keepalive is sent to POST /test/keepalive to let the Test Service know that the test is in progress.
- Test information and results are send using POST /test/configuration and POST /tests/details while the test is running
- When the test ends, a call to POST /test/end is made
Network Service — Bifröst Bridge
The network system that we have built to communicate to the device and do traffic shaping or dns manipulation is called the Bifröst Bridge. We are not altering the network topology and we are connecting the devices directly to the main network. Bifrost bridge is not required to run the tests and only optionally required when the tests require network manipulation such as overriding DNS records.
File Service
As we are running tests, we can opt to collect files produced by the tests and upload them to a storage depot via the file service. These include device log files, crash reports, screen captures, etc… The service is very straightforward from a consumer client perspective:

The file service is back by cloud storage and resources are cached for fast retrieval using Varnish Cache.
Database
We have chosen to use MongoDB as the database of choice for the Test Service because of its JSON format and the schema-less aspect of it. The flexibility of having an open JSON document storage solution is key for our needs because test results and metadata storage are always constantly evolving and are never finite in their structure. While a relational database sounds quite appealing from a DB management standpoint, it obstructs the principle of Plug-and-Play as the DB schema needs to be manually kept up to date with whatever tests might want.
When running in CI mode, we record a unique run id for each test and collect information about the build configuration, device configuration, test details etc. Downloadable links to file service to logs are also stored in the database test entry.
Test Runner — Maze Runner
In order to reduce the burden of each test case owner to call into different services and running the tests individually, we built a controller which orchestrates running the tests and calling different services as needed called Maze Runner.
The owner of the test suite creates a script in which he/she specifies the devices (or device types) on which the tests need to be run, test suite name and the test cases that form a test suite and asks Maze Runner to execute the tests (in parallel).
Here are the list of steps that Maze Runner does
- Finds a device/devices to run on based on what was requested
- Calls into the Device Service to install a build
- Calls into the Device Service to start the test
- Wait until the test in marked as “ended” in the Test Service
- Display the result of the test retrieved using the Test Service
- Collect log files using the Device Service
- If the test did not start or did not end (timeout), Maze Runner checks whether the application has crashed using the Device Service.
- If the crash is detected, it collects the coredump, generates call stack and runs it through a proprietary call stack classifier and detects a crash signature
- Notify the Test Service if a crash or timeout occurred.
- At any point during the sequence, if Maze Runner detects a device has an issue (the build won’t install or the device won’t start because it lost its network connectivity for example), it will release the device, asking the device service to disable it for some period of time and will finally get a whole new device to run the test on. The idea is that pure device failure should not impact tests.
Test frameworks
Test frameworks are well separated from automation services as they are running along tests on the devices themselves. Most tests can be run manually with no need for automation services. This was one of the core principle in the design of the system. In this case tests are manually started and the results manually retrieved and inspected when the test is done.
However test frameworks can be made to operate with automation services (the test service for example, to store the tests progress and results). We need this integration with automation services when tests are run in CI by our runner.
In order to achieve this in a flexible way we created a single abstraction layer internally known as TPL (Test Portability Layer). Tests and test frameworks call into this layer which defines simple interfaces for each automation service. Each automation service can provide an implementation for those interfaces.
This layer allows tests meant to be run by our automation to be executed on a completely different automation system provided that TPL interfaces for this system’s services are implemented. This enabled using test cases written by other teams (using different automation systems) and run them unchanged. When a test is unchanged, the barrier to troubleshooting a test failure on the device by the test owner is completely eliminated; and we always want to keep it that way.
Progress
By keeping the test framework independent of automation services, using automation services on an as required basis and adding the missing device features we managed to:
- Augment our test automation coverage on gaming consoles and reference applications.
- Extend the infrastructure to mobile devices (Android, iOS, and Windows Mobile).
- Enable other QA departments to leverage conducting their their tests and automation frameworks against our device infrastructure.
Our most recent test execution coverage figures show that we execute roughly 1500 tests per build on reference applications alone. To put things in perspective, the dev team produces around 10–15 builds on a single branch per day each generating 5 different build flavors (such as Debug, Release, AddressSanitizer, etc..) for the reference application. For gaming consoles, there are about 3–4 builds produced per day with a single artifact flavor. Conservatively speaking, using a single build artifact flavor, our ecosystem is responsible for running close to 1500×10 + 1500×3 ≈ 20K test cases on a given day.
New Challenges
Given the sheer number of tests executed per day, two prominent sets of challenges emerge:
- Device and ecosystem scalability and resiliency
- Telemetry analysis overload generated by test results
In future blog posts, we will delve deeper and talk about the wide ranging set of initiatives we are currently undertaking to address those great new challenges.
by Benoit Fontaine, Janaki Ramachandran, Tim Kaddoura, Gustavo Branco
Originally published at techblog.netflix.com on August 10, 2016.

