Netflix Billing Migration to AWS — Part III
In the billing migration blog post published a few weeks ago, we explained the overall approach employed in migrating our billing system to the cloud:
In this post, the database migration portion will be covered in detail. We hope that our experiences will help you as you undertake your own migrations.
Have you ever wondered about the elements that need to come together and align to get a complicated database migration right? You might ask, “What makes it complicated?”
Think of any challenge in database migration and pretty much all of them were there in this migration:
- Different hardware between source and target
- OS flavours
- Migration across heterogeneous databases
- Multiple datacenters — Netflix data center (DC) and AWS cloud
- Criticality of the transactional billing data
- Selective dataset migration
- Migration of constantly changing data, with minimal downtime
Billing, as most of you would agree, is the critical service for any company. The database is the most essential element in any migration and getting it right determines the success or failure of the whole project. The Netflix CDE (Cloud Database Engineering) team was tasked with migrating this critical subsystem database. The following sections describe some of key areas we focused on in order to ensure a successful migration.
Choice of the database
Billing applications have transactions that need ACID compliance to process the payment for charged transactions. RDBMS seemed the right choice for the datastore.

Oracle: As source database was in Oracle, migrating to Oracle in Cloud would avoid cross database migration, simplifying the coding effort and configuration setup. Our experience with Oracle in production gave more confidence with respect to its performance and scalability. However, considering the licensing costs and the technical debt required to migrate legacy data “as is”, prompted us to explore other options.
AWS RDS MySQL: Ideally we would have gone with MySQL RDS as our backend, considering Amazon does a great job in managing and upgrading relational database as a service, providing multi-AZ support for high availability. However, the main drawback to RDS was the storage limit of 6TB. Our requirement at the time, was closer to 10TB.
AWS Aurora: AWS Aurora would have met the storage needs, but it was in beta at that time.
PostgreSQL: PostgreSQL is a powerful open source, object-relational database system, but we did not have much in house expertise using PostgreSQL. In the DC, our primary backend databases were Oracle and MySQL. Moreover, choosing PostgreSQL would have eliminated the option of a seamless migration to Aurora in future, as Aurora is based on the MySQL engine.
EC2 MySQL: EC2 MySQL was ultimately the choice for the billing use case, since there were no licensing cost and it also provided a path to future Aurora migration. This involved setting up MySQL using the InnoDB engine on i2.8xlarge instances.
Production Database Architecture
High availability and scalability were the main drivers in designing the architecture to help the billing application withstand infrastructure failures, zone and region outages, and to do so with minimal downtime.
Using an DRBD copy in another zone for the primary master DB, helped withstand zone outages, infrastructure failures like bad nodes, and EBS volume failures. “Synchronous replication protocol” was used to enable the write operations on the primary node to be considered completed, only after both the local and remote writes have been confirmed. As a result, the loss of a single node is guaranteed to have no data loss. This would impact the write latency, but that was well within the SLAs.
Read replica setup in local, as well as cross region, not only met high availability requirements, but also helped with scalability. The read traffic from ETL jobs was diverted to the read replica, sparing the primary database from heavy ETL batch processing.
In case of the primary MySQL database failure, a failover is performed to the DRBD secondary node that was being replicated in synchronous mode. Once secondary node takes over the primary role, the route53 DNS entry for database host is changed to point to the new primary. The billing application being batch in nature is designed to handle such downtime scenarios. The client connection do not fallback but establish new connections that would point to the new primary after the Cname propagation is complete.

Choice of Migration Tool
We spent considerable time and effort in choosing the right tool for the migration. Primary success criteria for the POC was the ability to restart bulk loads, bi-directional replication, and data integrity. We focused on the following criteria while evaluating a tool for the migration.
- Restart bulk/incremental loads
- Bi-directional replication
- Parallelism per table
- Data integrity
- Error reporting during transfer
- Ability to rollback after going live
- Performance
- Ease of use
GoldenGate stood out in terms of features it offered which aligned very well with our use case. It offered the ability to restart bulk loads in case of failures (a few tables were hundreds of GB in size), and its bi-directional replication feature provided easy rollback from MySQL to Oracle.
The main drawback with GoldenGate was the learning curve in understanding how the tool works. In addition, its manual configuration setup is prone to human error, which added a layer of difficulty. If there is no primary key or unique key on the source table, GoldenGate uses all columns as the supplemental logging key pair for both extracts and replicats. We found issues like duplicate data at the target in incremental loads for such tables and decided to execute a full load during the cutover for those specific tables with no pre-defined primary or unique key. The advantages and features offered by GoldenGate far exceeded any challenges and was the tool of choice.
Schema Conversion and Validation
Since source and target databases were different, with data type and data length differences, validation became a crucial step in getting the data migrated while keeping the data integrity intact.
Data type mismatch took sometime to fix the issues stemming from it. One example — many numeric values in Oracle were defined as the Number datatype for legacy reasons. There is no equivalent type in MySQL. The Number datatype in Oracle stores fixed and floating-point numbers which was tricky. Some source tables had columns where Number meant an integer, in other cases it was used for decimal values, while some had really long values up to 38 digits. In contrast, MySQL has specific datatypes like Int, bigInt, decimal, double etc and a bigInt cannot go beyond 18 digits. One should ensure that correct mapping is done to reflect the accurate values in MySQL.
Partitioned tables needed special handling, since unlike Oracle, MySQL expects the partition key to be the part of the primary key and unique key. Target schema had to be redefined with proper partitioning keys to ensure no negative impact on application logic and queries.
Default value handling also differs between MySQL and Oracle. For the columns with a NOT NULL value, MySQL determined the implicit default value for the column. Strict mode had to be enabled in MySQL to catch such data conversion issues, as such transactions would fail and show up in the GoldenGate error logs.
Tools for schema conversion: We researched a variety of tools to assist in schema conversion as well as validation, but the default schema conversion provided by these tools did not work due to our legacy schema design. Even GoldenGate does not convert Oracle schema to the equivalent MySQL version, but instead depends on the application owners to define the schema first. Since one of our goals with this migration was to optimize schema, the database and application teams worked together to review the data types, and did multiple iterations to capture any mismatch. GoldenGate will truncate the value to fit the MySQL datatype in case of a mis-match. We relied heavily on data comparison tools and the GoldenGate error logs to help detect mismatches in data type mapping between source and target, in order to mitigate this issue.
Data Integrity
Once the full load completed and incrementals caught up, another daunting task was to make sure the target copy correctly maintained the data integrity. As the data types between Oracle and MySQL were different, it was not possible to have a generic wrapper script to compare hash values for the rowkeys to ensure accuracy. There are a few 3rd party tools which do the data comparisons across databases comparing the actual values, but the total dataset is 10 TB which was not easy to compare. Instead, we used these tools to match a sample data set which helped in identifying a few discrepancies related to wrong schema mapping.
Test refreshes: One of the ways to ensure data integrity was to do the application testing on a copy of the production database. This was accomplished by scheduling database refreshes from the MySQL production database to test. Considering production was being backed by EBS for storage, a test environment was easily created by taking the EBS snapshots off the slave, and doing a point in time recovery into test. This process was repeated several times to ensure data quality.
Sqoop jobs: ETL jobs and reporting were used to help with data reconciliation process. Sqoop jobs pulled data out of Oracle for reporting purposes. Those jobs were also configured to run against MySQL. With continuous replication between source and target, reports were run against specific time window on the ETLs. This helped in taking out the variation due to incremental loads.
Row counts was another technique used to compare the source/target and match them. This was achieved by pausing the incremental loads on the target and matching the counts on Oracle and MySQL. Results from row counts were also compared after full GoldenGate load of the tables.
Performance Tuning
Infrastructure: Billing application persisted data in the DC on two Oracle databases residing on very powerful machines, using IBM power 7, 32 dual core 64 bit multiprocessors, 750GB RAM, TB’s storage allocated via SVC MCS cluster which is 8G4 cluster with 4GB/sec interface running with RAID 10 configurations.
One major concern with the migration was performance, as the target database was consolidated on one i2.8xlarge server, using 32 vCPU and 244 GB RAM. The application team did a lot of tuning at the application layer to optimize the queries. With the help of Vector the performance team was able to find bottlenecks and eliminate them by tuning specific system and kernel parameters. See Appendix for more details.
High performance with respect to reads and writes was achieved by using RAID0 with EBS provisioned IOPS volumes. To get more throughput per volume, 5 volumes of 4TB each were used, instead of 1 big volume. This was to facilitate faster snapshots and restores.
Database: One major concern using MySQL was the scale of our data and MySQL throughput during batch processing of data by billing applications. Percona provided consulting support, and the MySQL database was tuned to perform well during and after the migration. The main trick is to have two cnf files, one while migrating the data and tweaking parameters like innodb_log_file_size to help with bulk inserts, and the second cnf file for the real time production application load by tweaking parameters like innodb_buffer_pool_instances to help with the transaction real time load. See Appendix for more details.
Data load: During POC, we tested the initial table load with indexes in on/off combination and decided to go with enabling all indexes before the load. The reasoning behind this was that index creation in MySQL is single threaded (most tables had multiple indexes), and so we instead utilized Golden Gate’s parallel load feature to populate the table with indexes in reasonable time. Foreign key constraints were enabled during the final cutover.
Another trick we learned was to match the total number of processes executing full and incremental load, to the number of cores on the instance. If the processes exceeded the number of cores, the performance of those data loads slowed down drastically as the instance would spend a lot of time in context switches. It took around 2 weeks to populate 10 TB in target MySQL database with the full loads and have incremental loads catch up.
Conclusion
Though the database piece is one of the most challenging aspects of any migration, what really makes a difference between success and failure is ensuring you are investing in the right approach up front, and partnering closely with the application team throughout the process. Looking back on the whole migration, it was truly a commendable effort by different teams across the organization, who came together to define the whole migration and make the migration a great success! Along with the individual and cross team coordination, it’s also the great culture of freedom and responsibility which makes these challenging migrations possible without impacting business.
Appendix
Database Tunables for Bulk Insert
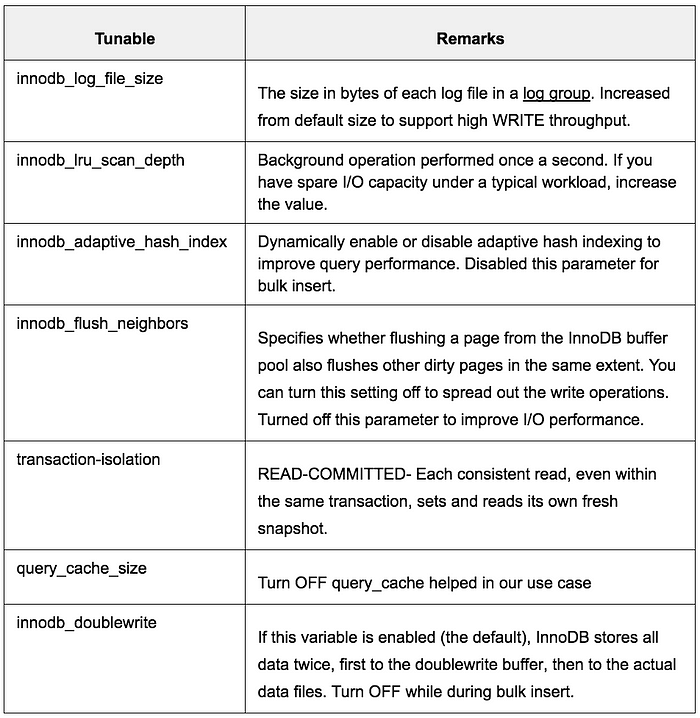
Database Tunables for High Transaction throughput

Storage
- RAID 0 with 5 x 4TB EBS PIOPS volumes
- LVM to manage two Logical Volume’s (DB and DRBD Metadata) within single Volume Group.
CPU Scheduler Tunables

Linux support automatic numa balancing feature that results in higher kernel overhead caused by frequent mapping/unmapping of application memory pages. One should disable it and instead use numa API in application or via sysadmin utility ‘numactl” to hint kernel on how its memory allocation should be handled.
VM Tunables

File system and IO Storage Metrics
— Jyoti Shandil, Ravi Nyalakonda, Rajesh Matkar, Roopa Tangirala
Originally published at techblog.netflix.com on August 1, 2016.

